






 Скопировать ссылку
Скопировать ссылку
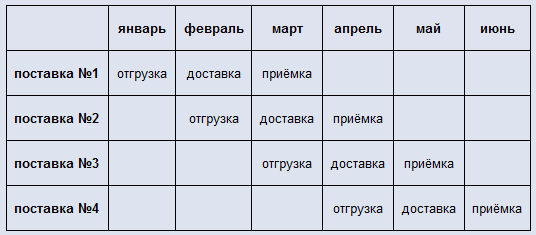
В данном примере, срок реагирования составляет три месяца, а период между двумя соседними поставками – месяц. Таким образом, в каждый момент времени у нас всегда в пути находятся три поставки на разных этапах, а на остатках лежит не больше месячной потребности. Но, чтобы эта система работала корректно, нам опять же нужен помесячный прогноз.
При этом обычно необходимо прогнозировать спрос большого количества позиций, а во время прогнозирования мы должны учесть общую динамику спроса по каждой позиции и характерную ей сезонность продаж. Объём таких расчётов оказывается слишком большим для ручного прогнозирования, поэтому нашей задачей становится создание автоматического алгоритма прогнозирования для обработки имеющейся статистики прошлого спроса по всем позициям. Ниже в статье мы будем обсуждать обработку одного ряда спроса по одной позиции. Но по аналогии надо анализировать последовательно данные по всем имеющимся в компании позициям.
Упрощённый классический метод
Первоначально необходимо определить общую динамику продаж: то есть для имеющегося ряда прошлого спроса Si надо построить линейный тренд – долговременную тенденцию изменения временного ряда, выражаемую прямой линией. В Microsoft Excel его уравнение можно получить, добавив на диаграмму временного ряда линейный тренд, а значение тренда для любого месяца Тi – используя функцию ТЕНДЕНЦИЯ. Именно благодаря этим значениям мы сможем рассчитать коэффициенты сезонности Ki для каждого i-того месяца в прошлом. Для этого надо разделить значение фактического спроса за каждый месяц на значение линейного тренда за этот же месяц:
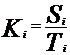
Тогда при наличии статистики хотя бы за два-три года появляется возможность рассчитать коэффициенты сезонности для каждого месяца года Km, где: К1 – коэффициент сезонности января, К2 – коэффициент сезонности февраля, К3 – коэффициент сезонности марта, и так далее... Делается это за счёт усреднения всех полученных коэффициентов сезонности за все года для соответствующего месяца:
 ,
,
где Lm – количество соответствующих месяцев в истории спроса.
Теперь, когда у нас есть эти коэффициенты, мы можем получить прогноз спроса Pi на любой будущий i-тый месяц, умножив соответствующий этому месяцу коэффициент сезонности Km на значение тренда Тi для этого месяца: Pi = Km · Ti.
Данный метод отличается от классического только отсутствием скользящего годового усреднения. По классике коэффициенты сезонности надо получать делением не на линейный тренд, а на значения этого скользящего среднего, и линейный тренд строится по скользящему. Но из-за этого теряется год статистики спроса, включая полгода самых ценных – последних данных, а так как зачастую вся статистика продаж по позиции в компании составляет всего полтора-два года, то подобная роскошь оказывается слишком расточительной.
Индуктивный метод Разгуляева
Данный метод был разработан мной для вычисления прогноза спроса в случаях, когда расчёт по классическому методу занимает слишком много времени из-за большого объёма информации или, вообще, невозможен из-за того, что тренд уходит в минус. Впоследствии он был реализован в нескольких автоматизированных системах, включая «Inventor» для Excel (http://zakup.vl.ru/64-inventor.html) и «Прогноз продаж» для 1С (http://automacon.ru/). Формула расчёта может показаться сначала сложной:

где X – это номер месяца, на который мы прогнозируем спрос, то есть количество месяцев, имеющихся в статистике прошлого спроса по позиции, плюс ещё один.
Но если мы обратим внимание на условие после каждой формулы в фигурной скобке, то увидим, что из всего этого каскада формул нам нужна только одна – та, которая подходит под наш объём имеющейся статистики прошлого спроса. Причём каждая формула состоит только из сложения, умножения и деления. Значок ∑Si – просто означает, что нам надо просуммировать все значения прошлого спроса, начиная с месяца, номер которого указан снизу этого значка, и заканчивая месяцем, номер которого указан сверху этого значка. Таким образом, получается, что и для понимания, и для реализации в корпоративной информационной системе оказывается проще именно этот метод. И если численные методы нахождения тренда в корпоративной информационной системе компании могут реализовать только программисты со специальным математическим образованием, да и то – для них это будет задачка на неделю-две, то уж сложение, умножение и деление – вам внедрит в течение суток любой программист!.. Да и считаться данный алгоритм будет на порядок быстрее.
Кроме этого у данного метода есть ещё ряд существенных плюсов – он никогда не будет прогнозировать отрицательные значения спроса при положительной прошлой статистике в отличие от классического метода. А ещё он – гибче, то есть быстрее реагирует на проявления динамики спроса. При этом, как и классический метод, индуктивный метод Разгуляева учитывает: как общую динамику спроса, причём, не привязываясь к линейности тренда, так и повторяющиеся из года в год сезонные влияния. Единственный его «недостаток» заключается в том, что вы не можете посчитать прогноз спроса на любой месяц, не посчитав предварительно прогноз спроса на все предыдущие месяца. То есть, если сейчас закончился январь, и вы хотите спрогнозировать спрос в мае, то вам сначала надо будет по имеющейся статистике спрогнозировать спрос в феврале, затем внести это значение в статистику, и на её основании спрогнозировать спрос в марте. После этого по такой же схеме спрогнозировать спрос в апреле и только затем в мае. Однако на практике нам редко нужно прогнозировать спрос через полгода, но не прогнозировать спрос в следующем месяце, поэтому данный недостаток – не так критичен. Ещё одну проблему в применении данного метода – возможность равенства нулю одного из знаменателей в формуле, легко решает переход на формулу строчкой выше, где диапазон суммирования в знаменателе будет – значительно больше, и такой ситуации точно не возникнет. А чтобы лучше разобраться с формулами, можно скачать Excel-файлы с примерами реализации обоих методов по ссылке: http://upravlenie-zapasami.ru/excel/
Оценка точности прогноза
Как только у нас появляются хотя бы два варианта прогнозирования – сразу же возникает вопрос: «А какой из них лучше?» – Однозначного ответа на него нет и быть не может, так как нет и никогда не будет самого лучшего метода прогнозирования – их надо проверять на ваших данных, чтобы оценить, какой из них лучше предсказывает ситуацию для ваших позиций в ваших каналах продаж. И здесь исследователей подстерегает одна ловушка в определении ошибки прогноза D. Самым распространённым вариантом расчёта такой ошибки является следующая формула:
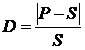 ,
,
где: P – это прогноз, а S – факт за тот же месяц.
Однако когда спрашиваешь пользователя этой формулы: «А чему равна ошибка, если факт равен нулю?» – то он попадает в понятное затруднение, ведь на ноль делить нельзя. Некоторые отвечают, что в таком случае D = 100% – мол, мы полностью ошиблись. Однако простой пример показывает, что такой ответ тоже – не верен:

Оказывается, что в варианте развития событий №2, когда мы лучше угадали спрос, чем в варианте №1, ошибка по данной формуле оказалась – больше. То есть ошиблась уже сама формула. Есть и другая проблема, если мы посмотрим на варианты №2 и №3, то увидим, что имеем дело с зеркальной ситуацией в прогнозе и факте, а ошибка при этом отличается – в разы!.. То есть при такой оценке ошибки прогноза нам лучше его заведомо делать менее точным, занижая показатель – тогда ошибка будет меньше!.. Хотя понятно, что чем точнее будет прогноз – тем лучше будет и закупка. Поэтому для расчёта ошибки советую использовать следующую формулу:
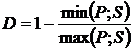
В таком случае для тех же примеров ошибка рассчитается иначе:
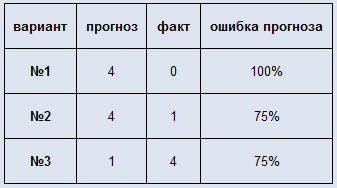
Как мы видим в варианте №1 ошибка становится равной 100%, причём это уже – не наше предположение, а чистый расчёт, который можно доверить машине. Зеркальные же варианты №2 и №3 – имеют и одинаковую ошибку, причём эта ошибка меньше ошибки самого плохого варианта №1. Единственная ситуация, когда данная формула не сможет дать однозначный ответ – это равенство знаменателя нулю. Но максимум из прогноза и факта равен нулю, только когда они оба равны нулю. В таком случае получается, что мы спрогнозировали отсутствие спроса, и его, действительно, не было – то есть ошибка тоже равна нулю – мы сделали совершенно точное предсказание.
Получение истории спроса
На протяжении всей предыдущей статьи мы работали с временным рядом прошлого спроса, однако обычно его в явном виде изначально в компании – нет. Дело в том, что данные о прошлых продажах, далеко не всегда являются историей спроса. Получению этой истории из имеющихся в корпоративной информационной системе данных можно посвятить целую статью – здесь же ограничимся перечислением влияющих факторов с небольшим объяснением по каждому.
Дефицит. Если товара не было, и продажи из-за этого были равны нулю, то данную статистику ни в коем случае нельзя использовать в «чистом» виде – ведь в таком случае мы будем сами создавать ситуацию такого же дефицита и в будущем. Поэтому дефицит нужно оценивать и прибавлять к продажам, чтобы получить историю спроса с его учётом.
Нехарактерно большой спрос. Иногда к нам приходят клиенты, которые забирают весь запас, или даже мы делаем дополнительный заказ под них. Такие отгрузки крайне редки, и держать под них запас – не выгодно, так как мы больше потеряем на хранение таких объёмов и обслуживание замороженных в запасы денег, чем выиграем от такой продажи, которой может больше никогда и не случиться. Однако в историю продаж эти операции попадают, и значит, их надо исключать.
Проведение маркетинговых акций. В случае если наши продажи были завышенными из-за проведения маркетинговых акций, то такую статистику продаж тоже нужно корректировать. Самый опасный случай – когда мы устраиваем распродажу неликвидов, они начинают продаваться, и мы на основании этих данных решаем ещё их закупить.
Отсутствие товаров-аналогов. На завышенный спрос может повлиять и отсутствие товаров-аналогов, когда клиент, не найдя то, за чем пришёл, берёт хоть что-нибудь подходящее – например позицию, спрос на которую мы хотим предсказать. При этом если вы в будущем не собираетесь допускать таких ситуаций, то спрос на исследуемую позицию заведомо не будет таким высоким.
Товары, отсутствие которых запирает продажи других позиций. В случае, когда у нас какие-то две позиции продаются обычно вместе, но какой-то одной из них долго не было, возможно, что продажи другой – тоже были заниженными. Например, если в нашей торговой точке не было сметаны, то и творог будет продаваться хуже. А значит, данную зависимость тоже надо учитывать и корректировать соответствующим образом прогнозы.
Цены. Всем понятно, что цена оказывают значительное влияние на объём продаж, а значит, в прогнозировании нам надо будет учитывать и этот фактор, если мы хотим добиться необходимой точности наших расчётов.














